Working with SQL Databases¶
Lux provides an extensible framework for users to pick their own execution backend for data processing. We currently support Pandas (lux.executor.PandasExecutor) and SQL (lux.executor.SQLExecutor) as the execution engine. By default, Lux leverages Pandas as its execution backend; in other words, the data processing code is performed as a set of Pandas operations on top of dataframe. In this tutorial, we further explain how Lux can be used with SQL with tables inside a Postgres database.
Note
You can follow a tutorial describing how Lux can be used with data inside a Postgres database in a Jupyter notebook. [Github] [Binder]
SQL Executor¶
Lux extends its visualization capabilities to SQL within Postgres databases. By using the SQLExecutor, users can create a LuxSQLTable that connects to a Postgres database. When the LuxSQLTable object is printed out, Lux displays a subset of the data and recommends a default set of visualizations to display.
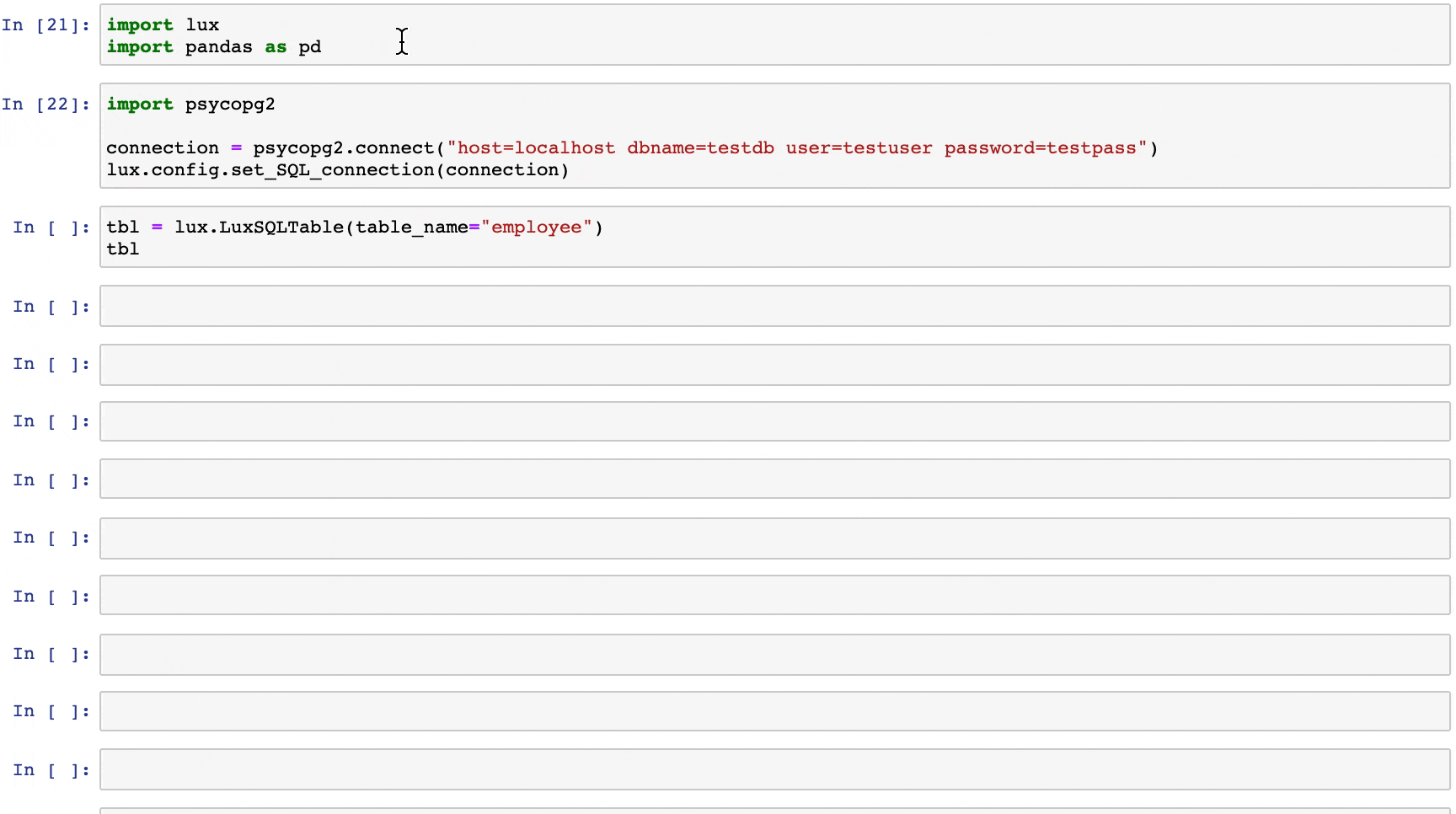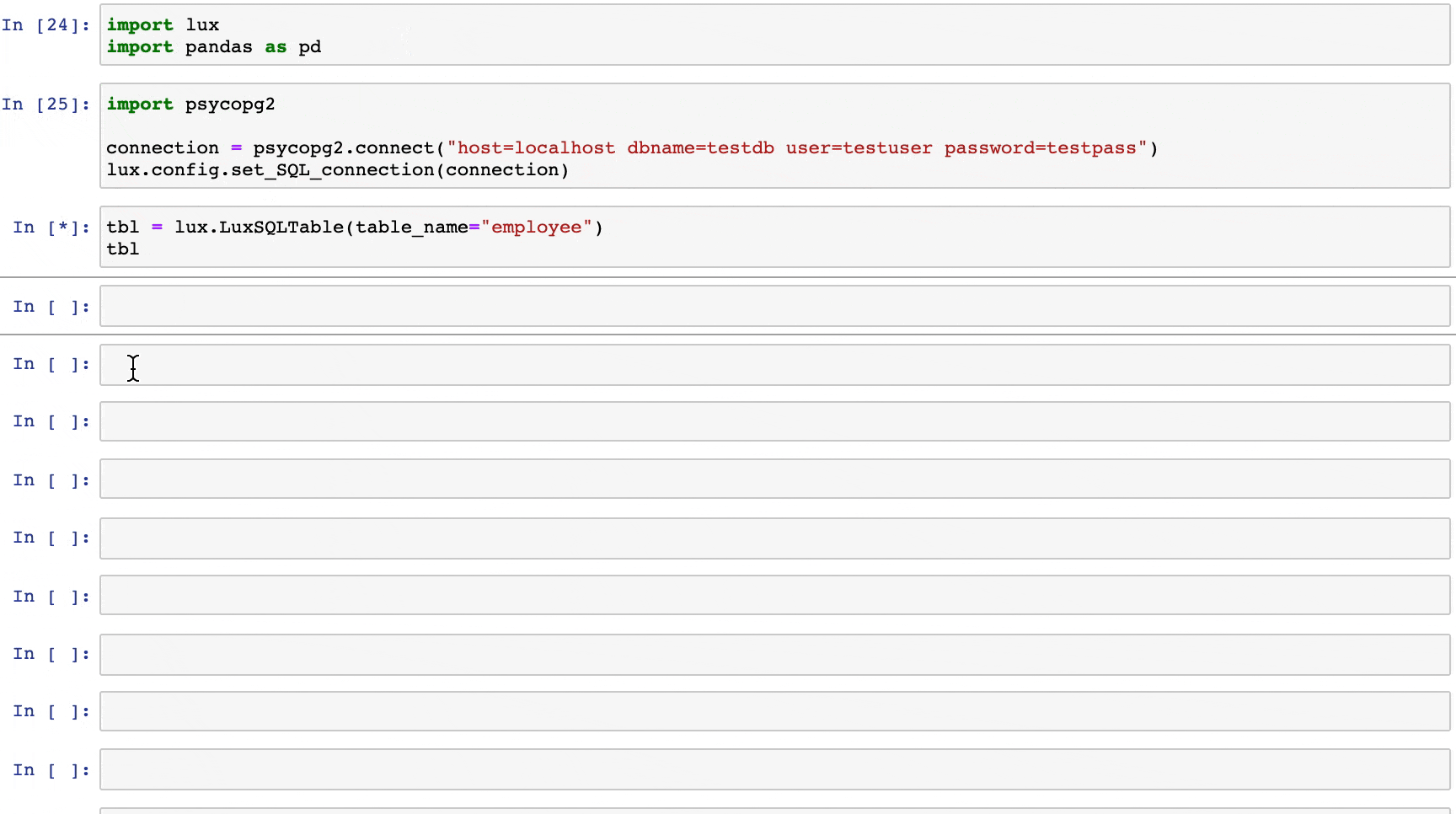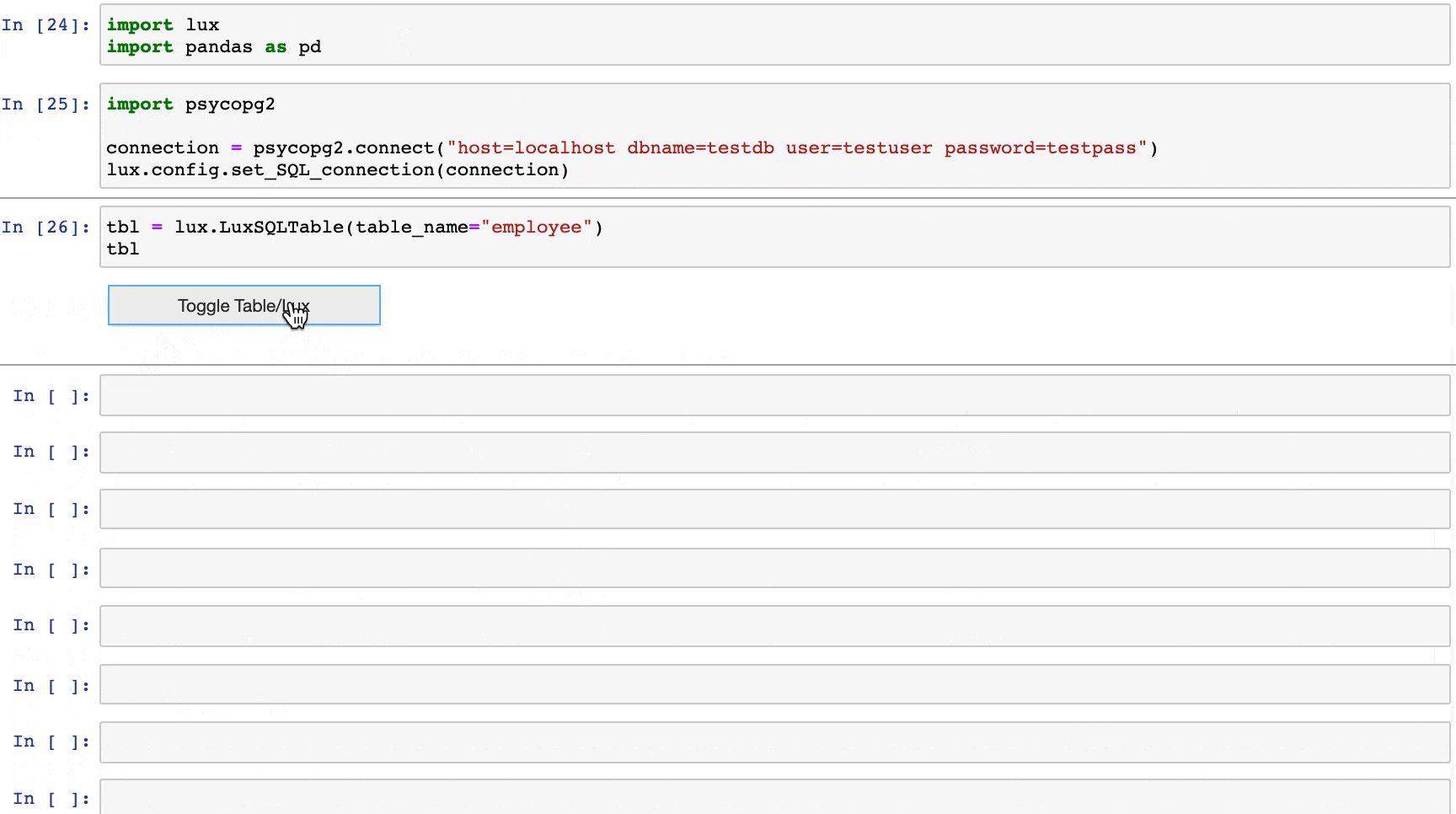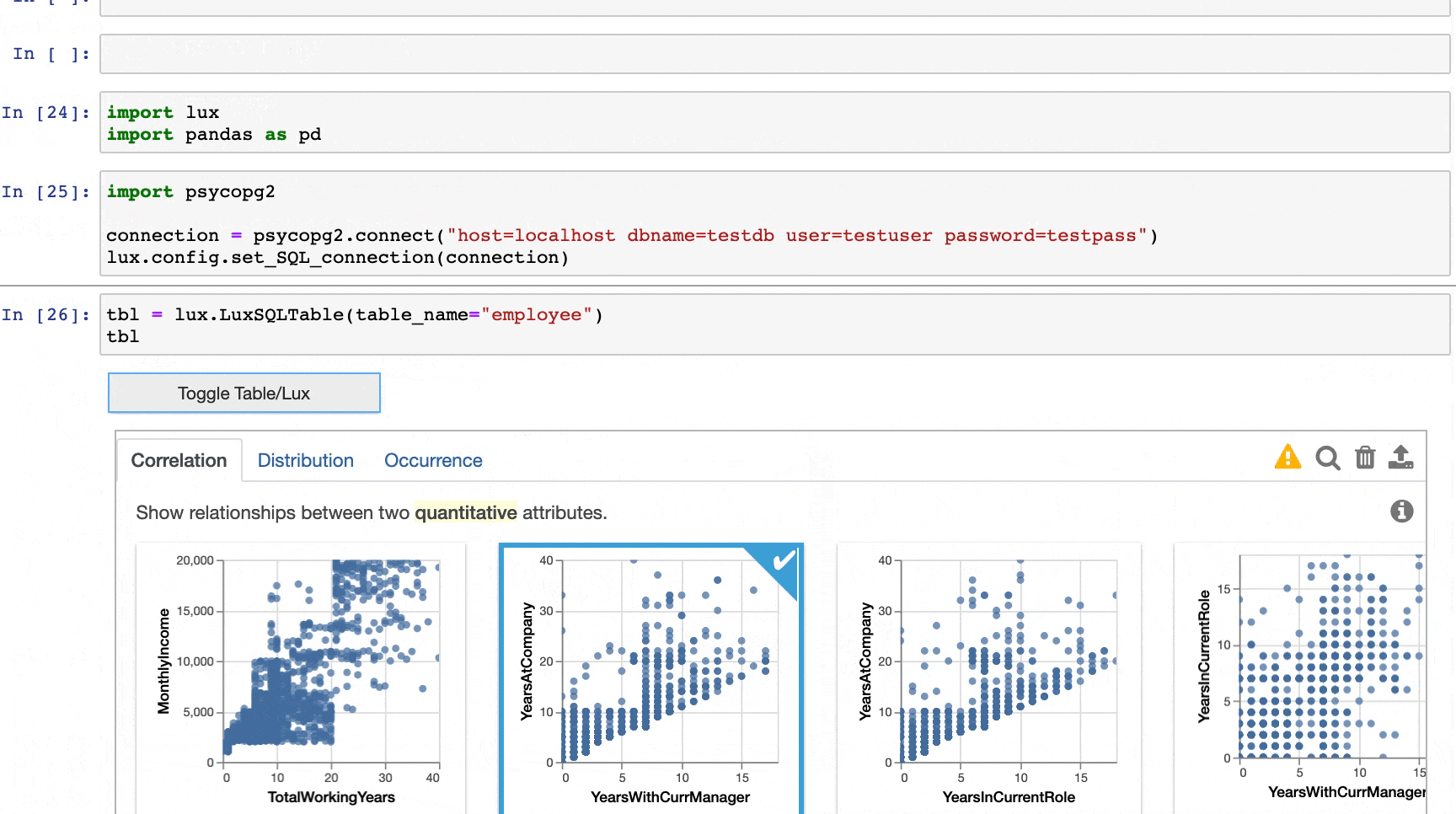
What is the SQL Executor?¶
It is common for data to be stored within a relational database, such as Postgres.
The execution engine in Lux processes the data in order to generate the data required for the visualization. By default, Lux uses Pandas as its execution engine.
However, fetching the data required for generating visualizations can be computationally expensive. Database users may not be able to pull in the entire dataset, either due to a lack of permissions or due to the data being too large to work with on a local machine. Thus, in order to leverage Lux’s capabilities, you can use the LuxSQLTable to work with data stored inside a Postgres database. A LuxSQLTable represents a SQL table with the Postgres database. The LuxSQLTable contains a skeleton of the dataframe schema and does not store the entire data in the database. (Underneath the hoods, LuxSQLTable is a database that serve as the LuxDataFrame for a table. However, note that since LuxSQLTable is not a dataframe, you cannot use the usual Pandas Dataframe functions on LuxSQLTable.)
Connecting Lux to a Database¶
Note
To run these examples with your own Postgresql database locally, please follow these instructions how to set up and populate the appropriate example database and table.
Before Lux can operate on data within a Postgres database, users have to connect their LuxSQLTable to their database. To do this, users first need to specify a connection to their SQL database. This can be done using psycopg2 or sqlalchemy SQL database connectors, shown as follows:
import psycopg2
connection = psycopg2.connect("dbname=postgres_db_name user=example_user password=example_user_password")
from sqlalchemy import create_engine
engine = create_engine("postgresql://postgres:lux@localhost:5432")
Note that users will have to install these packages on their own if they want to connect Lux to their databases.
Once this connection is created, users can connect Lux to their database using the set_SQL_connection command.
lux.config.set_SQL_connection(connection)
After the SQL connection is set, Lux fetches the details required to connect to your PostgreSQL database and generate useful recommendations.
Connecting a LuxSQLTable to a Table/View¶
LuxSQLTables can be connected to individual tables or views created within your Postgresql database. This can be done by specifying the table or view name in the constructor.
sql_tbl = LuxSQLTable(table_name = "my_table")
Alternatively, you can also connect a LuxSQLTable to a table or view by using set_SQL_table:
sql_tbl = LuxSQLTable()
sql_tbl.set_SQL_table("my_table")
Choosing an Executor¶
Once a user has created a connection to their Postgresql database, they need to change Lux’s execution engine so that the system can collect and process the data properly. By default, Lux uses the Pandas executor to process local data in the LuxDataframe, but users will use the SQL executor when their LuxSQLTable is connected to a database. Users can specify the executor that Lux will use via the set_executor_type function as follows:
lux_df.set_executor_type("SQL")
Once a LuxSQLTable has been connected to a Postgresql table and set to use the SQL Executor, users can take full advantage of Lux’s visual exploration capabilities as-is to discover insightful visualizations from their database.
SQL Executor Limitations¶
While users can make full use of Lux’s functionalities on data within a database table, they will not be able to use any of Pandas’ Dataframe functions to manipulate the data in the LuxSQLTable object. Since the Lux SQL Executor delegates most data processing to the Postgresql database, it does not pull in the entire dataset into the Lux Dataframe. As such there is no actual data within the LuxSQLTable to manipulate, only the relevant metadata required for Lux to manage its intent. Thus, if users are interested in manipulating or querying their data, this needs to be done through SQL or an alternative RDBMS interface.
Currently, Lux’s SQLExecutor does not support JOIN operation on SQL tables. Therefore, you cannot explore data and create recommended visualizations across multiple SQL tables only through Lux. We are consistently working on expanding the SQL capabilities of Lux, please let us know about how you’re using the SQLExecutor and how we can improve the functionality here !