Configuration Settings¶
In Lux, users can customize various global settings to configure the behavior of Lux through lux.config.Config. These configurations are applied across all dataframes in the session. This page documents some of the configurations that you can apply in Lux.
Note
Lux caches past generated recommendations, so if you have already printed the dataframe in the past, the recommendations would not be regenerated with the new config properties. In order for the config properties to apply, you would need to explicitly expire the recommendations as such:
df = pd.read_csv("..") df # recommendations already generated here df.expire_recs() lux.config.SOME_SETTING = "..." df # recommendation will be generated again here
Alternatively, you can place the config settings before you first print out the dataframe for the first time:
df = pd.read_csv("..") lux.config.SOME_SETTING = "..." df # recommendations generated for the first time with config
Change the default display of Lux¶
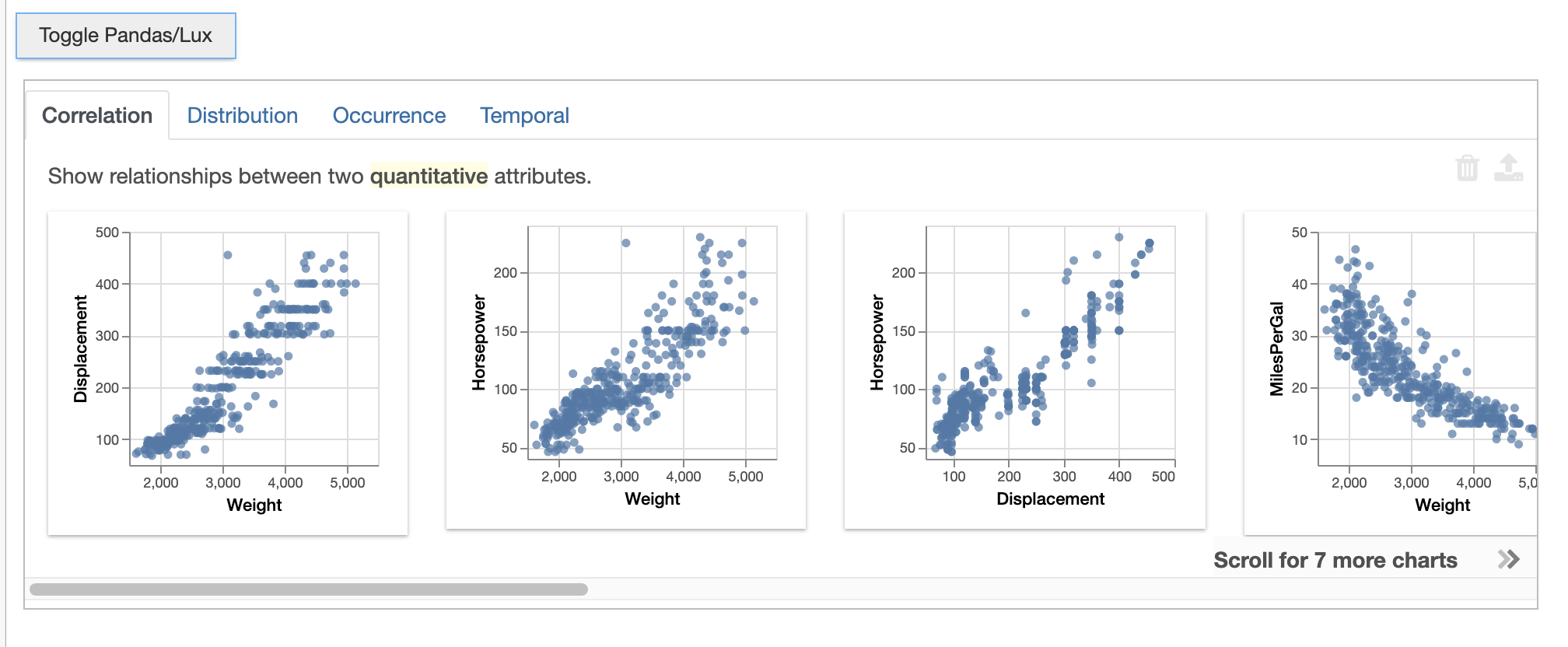
We can set the default_display to change whether the Pandas table or Lux widget is displayed by default. In the following block, we set the default display to ‘lux’, therefore the Lux widget will display first.
lux.config.default_display = "lux"
df
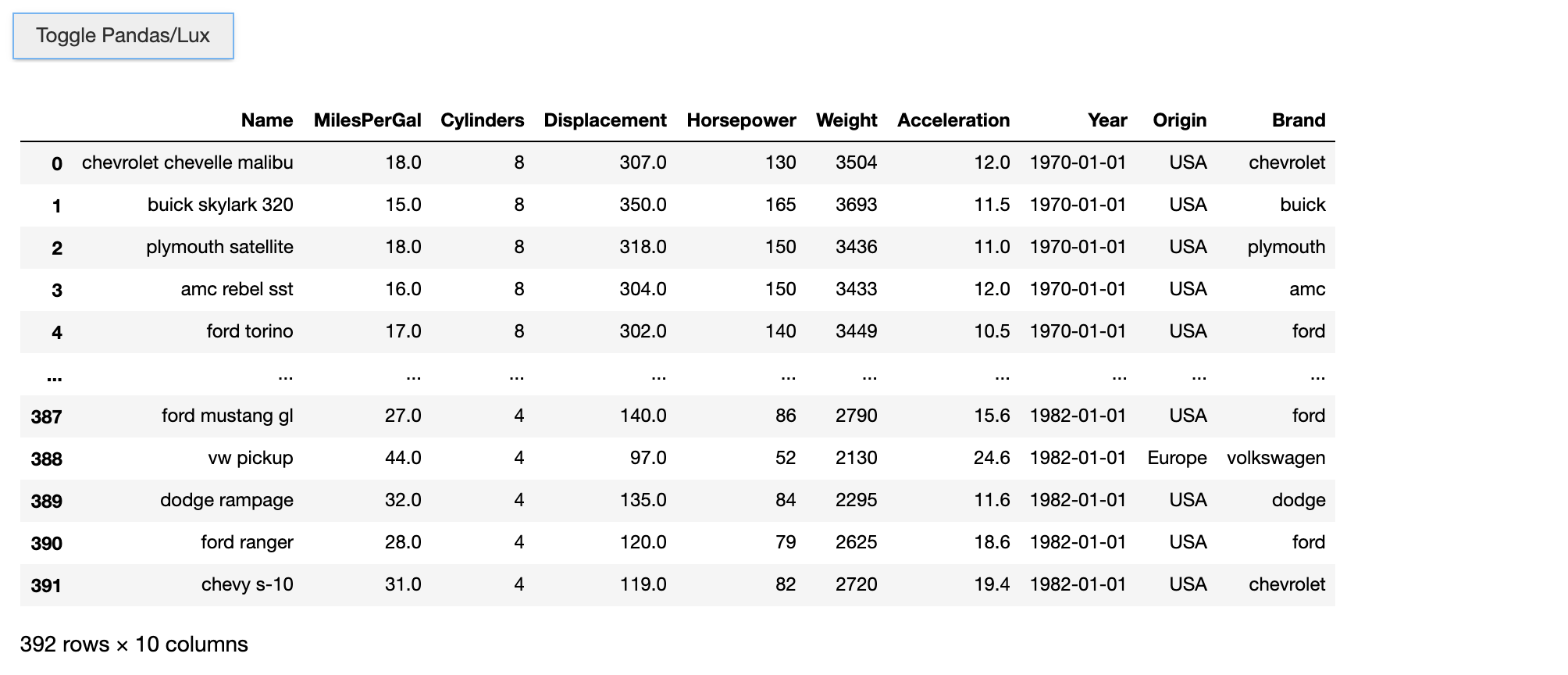
We can set the default_display back to ‘pandas,’ which would allow for the dataframe object to display first. You can still toggle to Lux/Pandas respectively using the ‘Toggle’ button.
lux.config.default_display = "pandas" # Set Pandas as default display
df
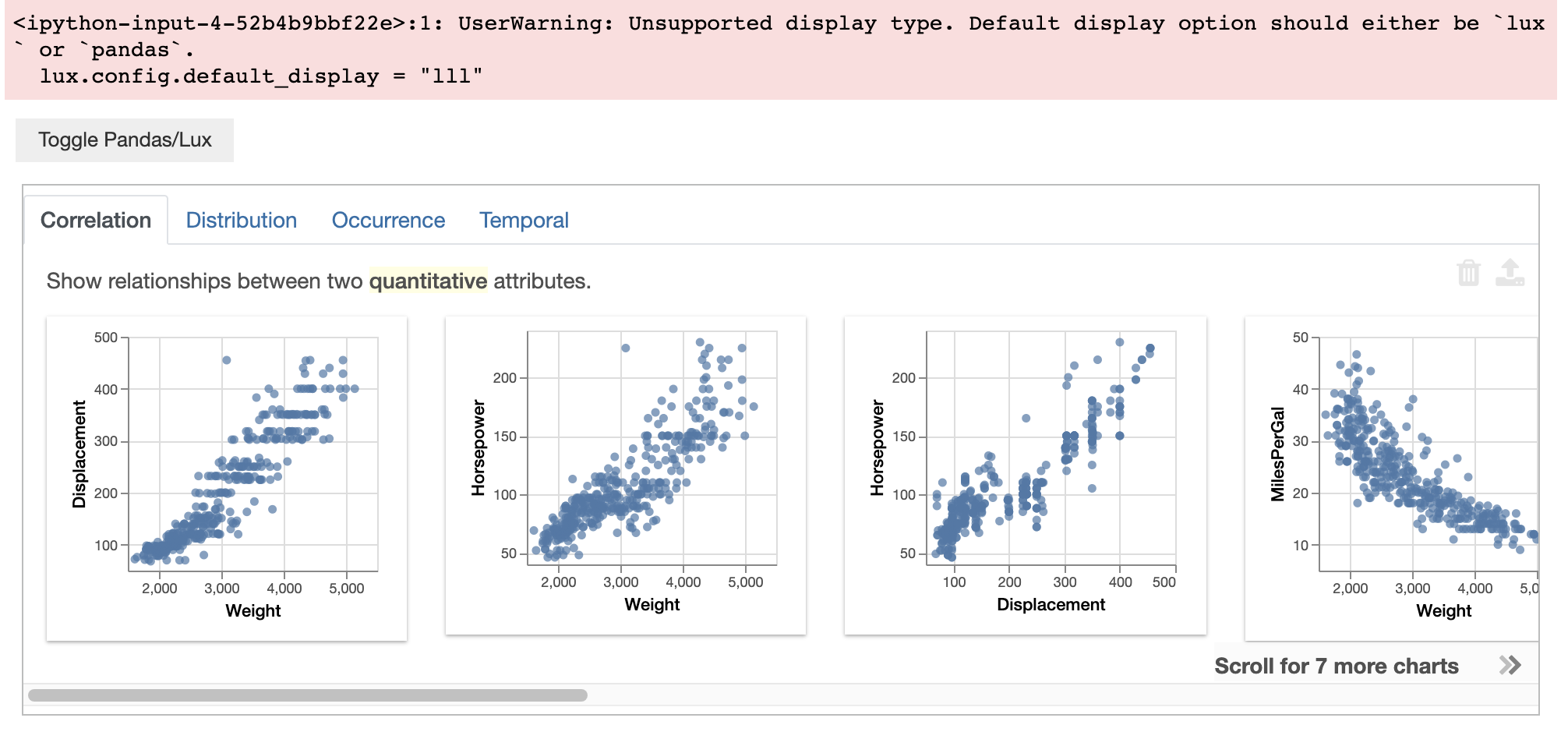
If you try to set the default_display to anything other than ‘lux’ or ‘pandas,’ a warning will be shown, and the display will default to the previous setting.
lux.config.default_display = "notpandas" # Throw an warning
df
Change the sampling parameters of Lux¶
To speed up the visualization processing, by default, Lux performs random sampling on datasets with more than 10000 rows. For datasets over 30000 rows, Lux will randomly sample 30000 rows from the dataset.
If we want to change these parameters, we can set the sampling_start and sampling_cap via lux.config to change the default form of output. The sampling_start is by default set to 10000 and the sampling_cap is by default set to 30000. In the following block, we increase these sampling bounds.
lux.config.sampling_start = 20000
lux.config.sampling_cap = 40000
If we want Lux to use the full dataset in the visualization, we can also disable sampling altogether (but note that this may result in long processing times). Below is an example if disabling the sampling:
lux.config.sampling = False
Disable the use of heatmaps for large datasets¶
In addition to sampling, Lux replaces scatter plots with heatmaps for datasets with over 5000 rows to speed up the visualization process.
We can disable this feature and revert back to using a scatter plot by running the following code block (but note that this may result in long processing times).
lux.config.heatmap = False
Default Renderer¶
Charts in Lux are rendered using Altair. We are working on supporting plotting via matplotlib and other plotting libraries.
To change the default renderer, run the following code block:
lux.config.renderer = "matplotlib"
Plot Configurations¶
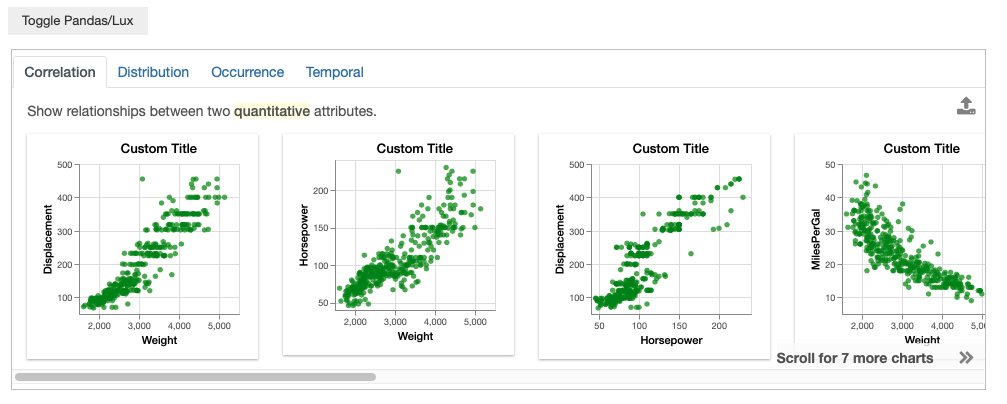
Altair supports plot configurations to be applied on top of the generated graphs. To set a default plot configuration, first write a function that can take in a chart and returns a chart. For example:
def change_color_add_title(chart):
chart = chart.configure_mark(color="green") # change mark color to green
chart.title = "Custom Title" # add title to chart
return chart
Then, set the plot_config to this function so that this function is applied to every plot generated.
lux.config.plot_config = change_color_add_title
The above results in the following changes:
See this page for more details.
Modify Sorting and Ranking in Recommendations¶
In Lux, we select a small subset of visualizations to display in each action tab to avoid displaying too many charts at once.
Certain recommendation categories ranks and selects the top K most interesting visualizations to display.
You can modify the sorting order and selection cutoff via lux.config.
By default, the recommendations are sorted in a "descending" order based on their interestingness score, you can reverse the ordering by setting the sort order as:
lux.config.sort = "ascending"
To turn off the sorting of visualizations based on its score completely and ensure that the visualizations show up in the same order across all dataframes, you can set the sorting as “none”:
lux.config.sort = "none"
For recommendation actions that generate a lot of visualizations, we select the cutoff criteria as the top 15 visualizations. If you would like to see only see the top 6 visualizations, you can set:
lux.config.topk = 6
If you would like to turn off the selection criteria completely and display everything, you can turn off the top K selection by:
lux.config.topk = False
Beware that this may generate large numbers of visualizations (e.g., for 10 quantitative variables, this will generate 45 scatterplots in the Correlation action!)